2023 iThome 鐵人賽
分享至
Hello 大家好!歡迎回來!昨天剛剛分享完深度強化學習 (Deep Reinforcement Learning),那今天我打算跟大家分享監督學習 (Supervised Learning)。事不宜遲,現在開始!
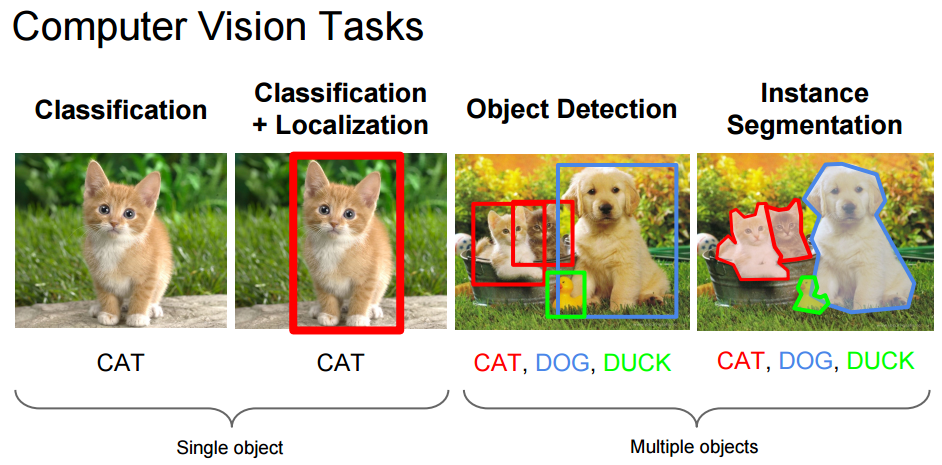
監督式學習是機器學習中的一種基本方法,它使計算機能夠從標記資料中學習並進行準確的預測或分類。通過利用由輸入-輸出對組成的訓練數據集,監督式學習算法可以推廣模式和關係,從而對未見數據進行預測。
之前已經介紹過一些了,那我們就快速帶過吧。
我是 Mr. cobble,明天見!
IT邦幫忙
 [1]
[1]

 iThome鐵人賽
iThome鐵人賽